Vision language models are quickly replacing traditional OCR systems, offering a deeper understanding of document structure and content. SmolDocling is one such model, designed as a compact document language model built for high-accuracy structural extraction. However, running inference for these models still requires considerable compute, often tied to expensive GPU servers.
Serverless infrastructure provides a more practical solution. In this post, a complete example is presented using Modal to download the SmolDocling model, store its weights in a persistent volume, and run inference in a fully serverless environment. This approach helps reduce costs, improves scalability, and removes the need to manage dedicated hardware.
Why serverless inference?
Document parsing is a transient task; maintaining always-on servers is inefficient.
Scalability is provided through automatic allocation of GPU-enabled containers when needed.
Costs are reduced by billing only for active inference runs.
Infrastructure complexity is minimized since Modal handles container orchestration and resource allocation.
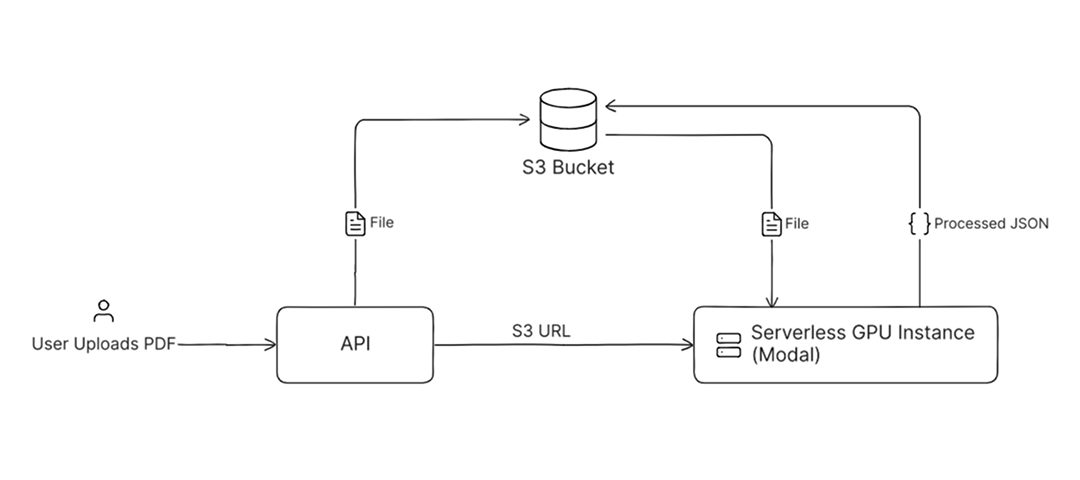
User uploads a PDF through an API, which stores the file in an S3 bucket. The API then passes the file URL to a serverless GPU instance running on Modal. The instance processes the document using SmolDocling and writes the extracted output back to the same bucket.
Step 1: Download and save the model in a persistent volume
The first step is to fetch the SmolDocling model from Hugging Face and store it in a persistent volume on Modal. This ensures that the model weights are downloaded only once and can be reused during inference runs.
The code below defines a small setup application to perform this task:
import os, shutilimport modalfrom huggingface_hub import snapshot_downloadMODEL_ID = "ds4sd/SmolDocling-256M-preview"VOLUME_NAME = "smoldocling-weights"TARGET_DIR = "/models"model_volume = modal.Volume.from_name(VOLUME_NAME, create_if_missing=True)app = modal.App("smoldocling-setup")image = modal.Image.debian_slim().pip_install("huggingface_hub", "transformers")@app.function( image=image, volumes={TARGET_DIR: model_volume}, timeout=600,)def download_model(): """Fetches model from HF and copies into the persistent volume.""" print(f"Downloading model: {MODEL_ID}") local_dir = snapshot_download(MODEL_ID) dst = os.path.join(TARGET_DIR, MODEL_ID.split("/")[-1]) if os.path.exists(dst): shutil.rmtree(dst) shutil.copytree(local_dir, dst) print("Model copied to volume.")
Once executed, the model weights will be available in the specified volume and ready for use during inference.
Step 2: Run inference in a serverless GPU container
With the model saved in a persistent volume, the next step is to set up a serverless GPU function that runs inference on uploaded PDFs. Modal handles container creation, GPU provisioning, and automatic cleanup.
This section configures a Modal function that:
Loads the model from the persistent volume
Accepts input PDFs from an S3-compatible bucket
Processes each page using ONNX runtime and SmolDocling
Saves the extracted structure as JSON and images back to the bucket
Define the Modal function that will run inference:
This function processes each page of a PDF and extracts structured content in Markdown format, along with images and raw tags, all stored back in the bucket.
To trigger inference manually from a local entrypoint:
@app.local_entrypoint()def main(): run_inference.remote("<R2_KEY>") # replace with the uploaded PDF key
Run the inference using the Modal CLI:
modal run smoldocling_inference.py
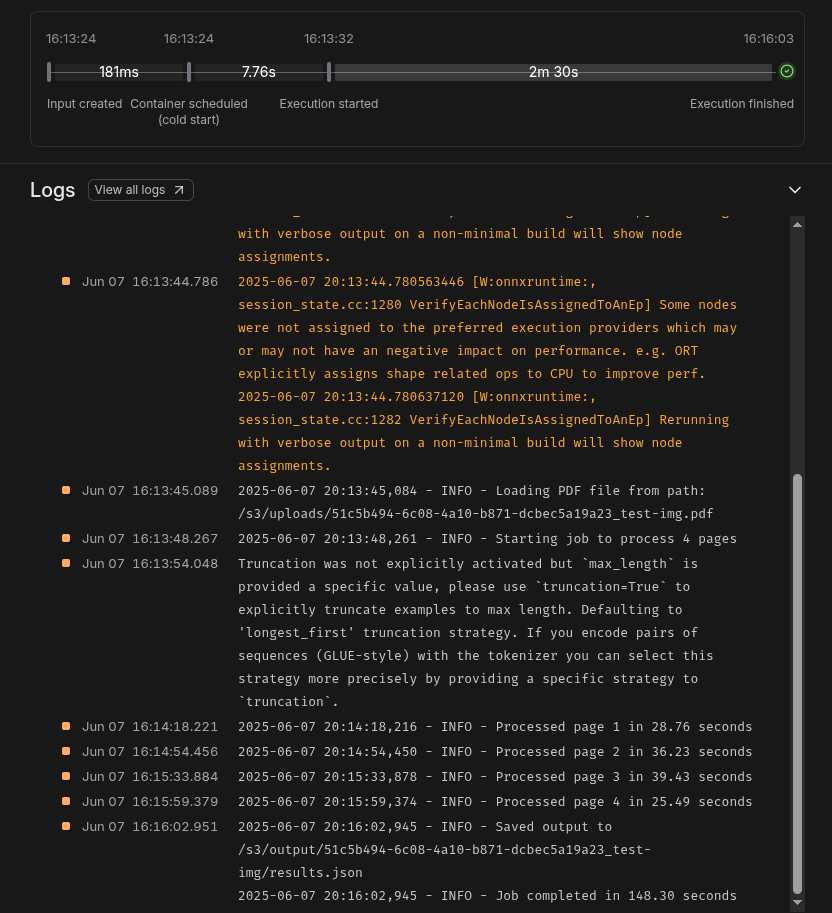
While the inference job is running, logs can be monitored in real-time through the Modal CLI or the Modal dashboard. Once complete, the processed results can be verified in the configured S3 bucket under the output path.
This setup demonstrates how SmolDocling can be deployed in a fully serverless environment using Modal. By separating model download and inference steps, and leveraging persistent volumes and GPU-backed containers, document parsing becomes efficient, scalable, and cost-effective. The same pattern can be adapted for other vision-language models with minimal changes.